

Prologo: Llama-3 es el ultimo modelo de iA de Meta antiguo Facebook, nos encontramos ante un sistema de código-abierto, situado cronológicamente en abril-2024, este post esta dedicado a la toma de contacto con la ultima versión de la iA-Meta.
Qué es Llama-3
-. Llama-3 modelo iA de Meta. Es un modelo de lenguaje de gran tamaño LLM, de código abierto “Open-Source”, es una arquitectura de red neuronal Transformers pero utiliza una variante llanada modelo Megatron-Turing (MT-NLG) desarrollada por Microsoft y NVIDIA. Referente a su Ventanas-Contexto-iA es de 8.192 tokens y tenemos dos versiones, con 8.000 y 70.000 millones de parámetros, y un futuro con 400.000 millones de parámetros.
Aclaremos algunos conceptos:
- .Que son los Transformers: Arquitectura-red-neuronal, Los transformers son un tipo de arquitectura de Network-Neuronal que transforma o cambia una secuencia de entrada en una secuencia de salida. ¡Como hace esto! Aprendiendo del contexto y rastrean las relaciones entre los componentes de la secuencia. Los Transformers están reemplazando en determinadas ocasiones a las Network-Neuronal convolucionales y recurrentes.
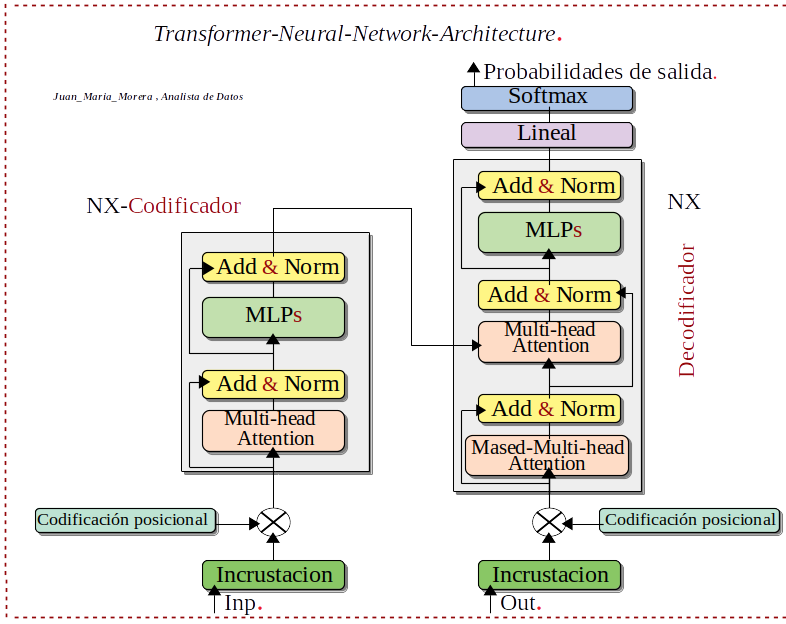
- .Que es LLM: Un Large-Language-Model o LLM, conocido también como modelo de lenguaje de gran tamaño, este modelo de lenguaje se compone de una Network-Neuronal con muchos muchos parámetros y un entrenamientos de grades cantidades de datos. Estos datos están sin etiquetar, entrenamiento mediante Aprendizaje-Autosupervisado.
- .Que son las Ventanas-Contexto-iA: es el texto que la iA puede leer y lo recuerda durante la sesión. El tamaño de la Ventanas-Contexto-iA, es el tamaño asimilado por la iA, este texto se mide en Tokens. Porgamos algún ejemplo de la versión mas básica: GPT-4-estándar 8000-tokens, del modelo Gemini-1.5 de Google 128000-tokens y Llama-3 de 8.192-tokens . Estos datos se sitúan cronológicamente a principio del 2024.
Entrenamiento
-. Hardware que se utiliza para el entrenamiento para Llama-3 modelo iA de Meta con un cluster 24000-GPUs. Los datos de entrenamientos que se han utilizados 15-Terabyte de Tokens obtenidos de fuentes-publicas.
-. Software que se utiliza para el entrenamiento para Llama-3 modelo iA de Meta con la la nueva biblioteca-Torchtune nativa de PyTorch para implementaciones fácilmente con LLMs. Esta biblioteca nos ofrece recetas de entrenamiento eficientes y modificables, escritas completamente en PyTorch.
Que nos proporciona Torchtune-PyTorch:
- Implementaciones nativas de PyTorch de LLM, utilizan bloques de construcción modulares y componibles.
- Recetas de entrenamiento fáciles de usar y manipulabes para la comunidad con técnica de ajuste fino (LoRA, QLoRA): referente a los Framework por ahora solo tiene PyTorch.
- Configurar fácilmente recetas de entrenamiento en YAML, Evaluación, Cuantificación y Inferencia
- Pose soporte para datos mas populares y plantillas para empezar con la capacitación.
Aclaremos algunos conceptos sobre Parámetros & tokens :
- .Qué son los tokens: unidad de testo del modelo, Los tokens son grupos de caracteres que representan la unidad fundamental del texto. Generados por un algoritmo tokenizador, puede ser una palabra pero tiene en cuenta todos los caracteres, hasta los emojis, esto depende del idioma, del modelo utilizado, etc. La proporción adecuada a considerar: (En Inglés: una palabra mas o menos 1.3 tokens) . (En Español: una palabra más o menos 2 tokens).
- .Que son los Parámetros-iA: Parámetros & tokens, Es un elemento de un sistema que identifica al tipo-sistema y evaluá su rendimiento, estado, la cantidad de parámetros mide el tamaño del modelo, es un valor internos dentro del modelo-iA, determinan el vínculo entre tokens y datos. En resumen: la cantidad de parámetros mide el tamaño del modelo y la cantidad de tokens determina el tamaño del conjunto de datos de entrenamiento .
- .Que son Entrenamiento & Inferencia: los modelos-iA lo primero es Entrenarlos ¡con que! con una gran cantidad de datos de todo tipo, de estos extraemos tendencias, parámetros, etc Tenemos un modelos-iA-preentrenada aplicaremos tareas específicas, mediante Inferencia estas Inferencia es el proceso por el cual se derivan conclusiones a partir de premisas o hipótesis iniciales.
Acceso
Nota: Este post falta el acceso, el propósito era usar la versión en ingles ya que en castellano en este momento no esta disponible y es interesante usarlo en castellano ¡parece ser tener diferencias de rendimiento! entre la dos versiones.
Recopilando:
En este modelo iA de Meta “Llama-3 se pone a disposición de la comunidad, ya que es de código abierto “Open-Source”. La versión mas potente de este modelo Llama-3 de eminente aparición con 400.000 millones de parámetros es una autentica barbaridad, la dos versiones, con 8.000 y 70.000 millones de parámetros, son descargable en ordenadores ¡mas o menos! Domestico, con una buena tarjeta GPUs.
- Referencias: moreluz.entorno
- Referencias: Meta