

Prologo: Los Transformer es un salto adelante en el procesamiento-lenguaje-natural PLM resuelve tareas como secuencias y dependencias de largo alcance. Los Transformer implementa una arquitectura codificador-decodificador sin Recurencias ni Convoluciones.
Que son Transformers
-. Los Transformers podemos considerarlos como una Arquitectura-Neural-Network “o” un nuevo tipo de red-neuronal de Procesamiento-Lenguaje-Natural PLM, esto se procesaba con redes-neuronales-recurentes RNN y se procesan de forma secuencial. Pero ¡irrumpieron los Transformers! estos tienen un mecanismo les permite comprender las relaciones de largo alcance; palabras, oración o párrafo, consigue captar el contexto del lenguaje. Los Transformers no tiene unidades recurrentes y necesita menos tiempo de entrenamiento que las Arquitecturas-Neuronales Recurrentes. Son perfectos ¡por ahora! Para LLM, conocido como modelo de lenguaje de gran tamaño.
Aclaremos algun concepto:
- .Que es LLM: Un Large-Language-Model o LLM, conocido también como modelo de lenguaje de gran tamaño, este modelo de lenguaje se compone de una Network-Neuronal con muchos muchos parámetros y un entrenamientos de grades cantidades de datos. Estos datos están sin etiquetar, entrenamiento mediante Aprendizaje-Autosupervisado.
-. Los Transformers son una arquitectura de Deep-Dearning, basada en el mecanismo de atención de múltiples cabezales. Los tokens son grupos de caracteres que representan la unidad fundamental del texto. a través del mecanismo de atención paralelo de múltiples cabezales que permite amplificar la señal de los tokens clave y disminuir los tokens menos importantes.
Aclaremos algun concepto:
- .Qué son los tokens: unidad de testo del modelo, Los tokens son grupos de caracteres que representan la unidad fundamental del texto. Generados por un algoritmo tokenizador, puede ser una palabra pero tiene en cuenta todos los caracteres, hasta los emojis, esto depende del idioma, del modelo utilizado, etc. La proporción adecuada a considerar: (En Inglés: una palabra mas o menos 1.3 tokens) . (En Español: una palabra más o menos 2 tokens).
- .Que es Deep-Learning: Aprendizaje-Profundo, es una parte de Machine-Learning (ML) que se basan en Redes-Neuronales-Artificiales (RNA) con el aprendizaje de características o aprendizaje de representaciones que detectan o clasifican características a partir de datos sin procesar. ¡Por que profundo! Por el uso de múltiples Capas-Red. Los métodos son; supervisados , semisupervisados o no-supervisados. Esta Deep-Learning de Redes-Creencias-Profundas pueden ser Redes-Neuronales-Recurrentes, Redes-Neuronales-Convolucionales y Transformer.
Arquitectura:
-. Transformers-Arquitectura-Neural-Network, tienen los mismos componentes primarios.
- Tokenizadores, que convierten texto en tokens.
- Una Capa-Incrustación, que convierte tokens y posiciones de los tokens en representaciones vectoriales.
- Capas-Transformadoras, que realizan transformaciones repetidas sobre las representaciones vectoriales, obteniendo cada vez más información, todo estos tienen capas alternas de atención y retroalimentación.
- Capa-Desintegración, genera representaciones vectoriales finales en una distribución de probabilidad sobre los tokens.
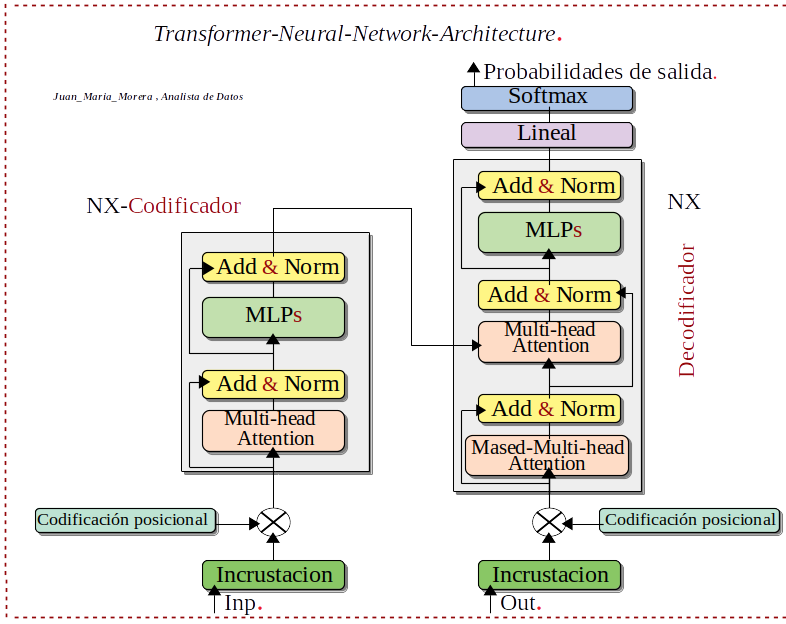
-. Las capas de los Transformers pueden ser de dos tipos codificador y decodificador.
-. Los Transformers normalmente es una estructura codificador–decodificador, pero no es la única los modelos GPT son de un decodificador.
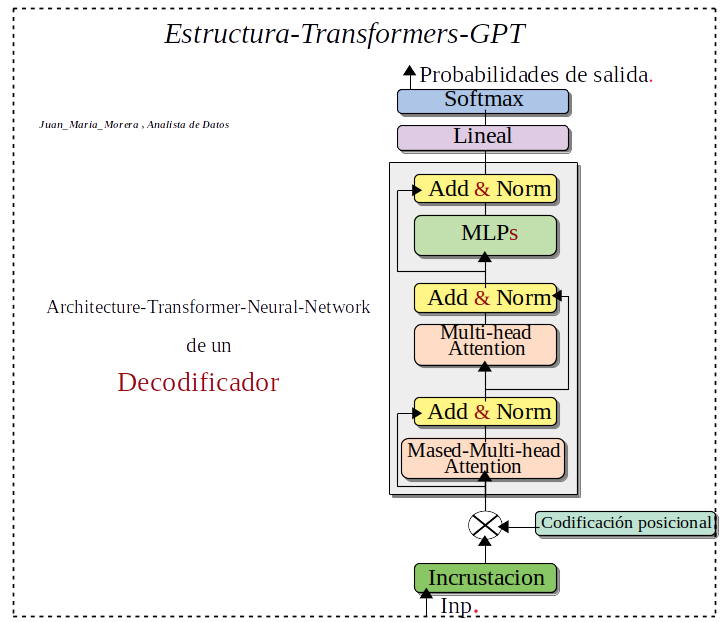
Descripción del diagrama:
- Inp: La entrada al Transforme es una secuencia de Tokens, donde cada Token representa una palabra o subpalabra en el texto de entrada.
- Incrustación: La capa de incrustación convierte cada Token en un vector de números reales.
- Codificación posicional: La capa de codificación posicional agrega información posicional a cada vector de incrustación. Esto es importante porque los transformes no son sensibles al orden de las palabras en la entrada.
- Atención multicabezal: La capa de atención multicabezal es el componente central del transforme. La atención permite que el modelo aprenda relaciones de largo alcance entre diferentes palabras en la entrada.
- Add & Norm: Las capas Add & Norm se utilizan para agregar y normalizar las salidas de la capa de atención multicabezal.
- MLP: La capa MLP es una Red-Neuronal-Perceptrón-Multicapa que se utiliza para procesar las salidas de la capa Add & Norm.
- Softmax: La capa softmax se utiliza para convertir las salidas del decodificador en probabilidades de salida.
-. Resumiendo el Decodificador generar la salida de texto, tiene varias capas, cada una de las cuales contiene un mecanismo de atención multi-cabeza, una capa de red neuronal totalmente conectada y una capa de softmax.
Implementación
-. El modelo Transforme se implementa con dos Frameworks de Deep-Learning como Keras & TensorFlow pero esta perdiendo importancia, al la do del rey del charco que es PyTorch.
-. Este Frameworks de PyTorch para el modelo Transforme tiene biblioteca producida específicamente para Large-Language-Model o LLM, conocido también como modelo de lenguaje de gran tamaño, tiene la opción de utilizar Transforme previamente entrenados. Este enfoque es altamente recomendado debido a su eficiencia y eficacia.
-. La biblioteca PyTorch–Transform https://huggingface.co/docs/transformers/en/index proporciona acceso a una amplia colección de modelos previamente entrenados. Estos modelos están entrenados en texto masivo. conjuntos de datos y se pueden ajustar para diversas tareas.
Pasemos a su instalación con Google-Colaboratory :
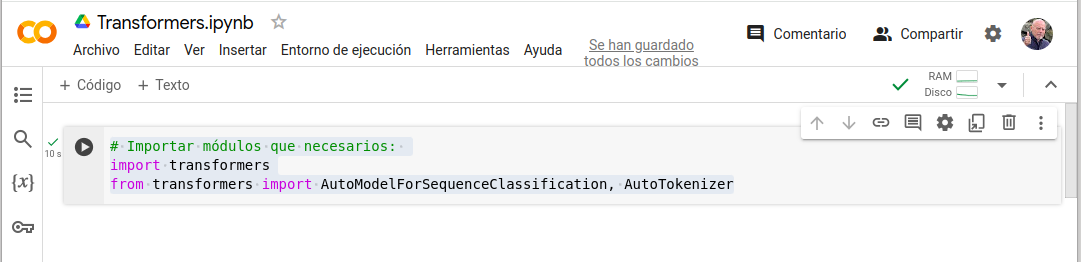
- # Importar módulos que necesarios:
- import transformers
- from transformers import AutoModelForSequenceClassification, AutoTokenizer
- # Cargue un modelo previamente entrenado y un tokenizador:
- model_name = «bert-base-uncased» # Example model
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- model = AutoModelForSequenceClassification.from_pretrained(model_name)
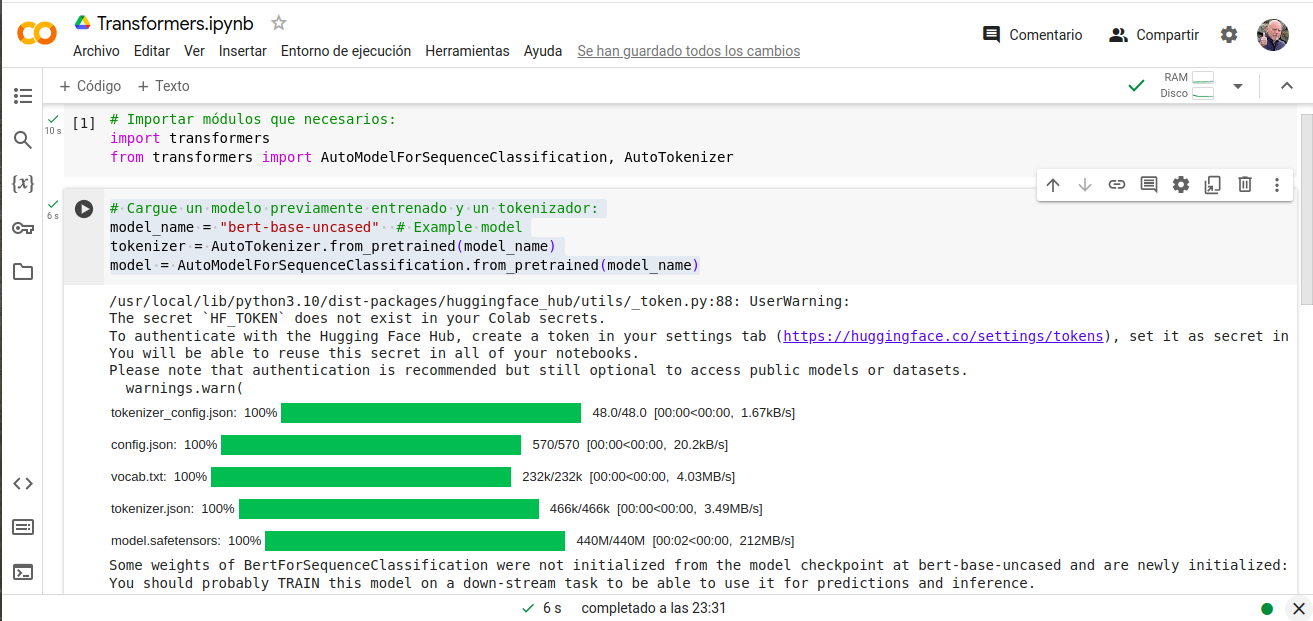
Nota: Tomemos esta practica como una toma de contacto, se pude mejorar notablemente. Lo interesante esta en que; hemos cargado el modelo-previamente-entrenado con éxito.
Recopilando:
Los Transformers son una Arquitectura-Red-Neuronal o una Red-Neuronal potente que es flexible y se utilizado para lograr resultados de última generación en una amplia gama de tareas de procesamiento del lenguaje natural. Se a conseguido la próxima generación del modelo basado en el Large-Language-Model LLM lo que llamamos inteligencia artificial iA.
- Referencias: moreluz.entorno